
Natural Language Processing & Social Sciences
This is an article explaining how the state of the art natural language processing (NLP) models can be used in the social sciences. Additionally, a few examples will be given using the GPT-3 NLP model developed by OpenAI.
Table of Contents
- Description
- Possibilities
- Relevance
- Example
- Conclusion
Description
At its core, a natural language processing tool will predict what text it should put out after processing the input text. Usually, sophisticated types of neural networks will be used, a machine learning construct.
Possibilities
Frequently-used ways to process text with NLP models include the following:
Text continuation: this is the most basic type of task a natural language processing model can be given. Based on probabilities, it will continue the input text, only constrained in length by the number of cycles the model is allowed to run for. You might input the sentence: “Smoking is ” where the model might first spit out the word “bad” but if run a few more cycles this might be “bad for your health”.
Answering questions: again, based on the constraints given, the model will return an answer to the question given, open-ended or yes-or-no. You can even ask NLP models to write essays on a given topic, albeit they perform quite poorly when asked about exact sciences; the real understanding is just not there yet. Depending on the definition used, you could argue language models do not currently have an understanding of other topics, too. It is just that for social-science-related questions it is easier to predict the correct word that would follow after each other one. This is probably partly the case as social sciences are relatively more argument-based in nature and tangible social science-related arguments usually follow a similar pattern. When you enter the realm of mathematical intuition, things tend to become more abstract, variable and complicated. Notice that all coming examples could be argued to be a subset of this example but the extra specificity is given for informational reasons.
Summarisation: a piece of text is given as the input and a summarisation subject to previously specified constraints is returned as the output. Some sophisticated NLP models are even able to output the summarisation as if it were for a 2nd grader. Usually, these models are fairly good at picking up what it is that should be included in the summary, probably because of the same line of reasoning given in the last example: writing a summary usually requires looking at similar phrases that indicate importance in-text and some grammatical ‘understanding’ seems to be present in these models. This notion of understanding is something to think about. These models estimate the likelihood of some piece of text coming after the last, but in what ways do we differ from that? It is not so clear how to answer such a question. This does not mean there is a high probability that we are on some level similar to these models, the possibility simply exists.
Finding the answer in-text: this is an example that is somewhat relating to the last example. Here, the text provided is given to the model together with a question relevant to the provided text. As with the summary, this will usually be an easy task for these models, but once the model is asked to abstract from the information given in the text, it can have difficulties with inter- or extrapolating the ideas effectively.
Classifying text: this, too, is relevant to the previous examples. One example of this would be to ask the model to classify the given text as either containing a positive, neutral or negative sentiment. This can be handy to analyse the sentiment of a large number of social media posts relating to some topic.
Writing code: to reinstate, the model is essentially a predictor of what text will come next (to be precise, often models predict one ‘token’ at a time). These models are trained on labelled or unlabelled data, the former is chosen when the streamlining of some specified NLP task is specified and the latter when more freedom is desired in using the model. An example of labelled data would be a lap of text with a corresponding summary, labelled accordingly. As this data usually contains rudimentary examples when it comes to code, because of its learning nature the model will usually be bad at predicting what to return for edge cases or how to extrapolate on its ‘knowledge’ to solve different coding problems. Therefore, the code a model is able to predict well will usually be associated with a standard, known coding problem.
The input of an example taken from OpenAI’s website:
Use list comprehension to convert this into one line of JavaScript:dogs.forEach((dog) => {car.push(dog);});JavaScript one line version:With the output returned by GPT-3:
dogs.forEach(dog => car.push(dog))
Unless your specific problem has many similarities to some of the data entries, e.g. only a different order of executions, your specific problem input will not be answered satisfactorily.
Relevance
Based on the examples given above, one can distil three areas of use for NLP in the social sciences:
1. A tool for education: for all of the examples given it holds that the model is capable of returning outputs based on what data had been fed to the model. Given that what is fed is what we already know and the ability of the model to build on that knowledge is not as sophisticated yet as the ability to recall the information in different ways, NLP models can be seen as tools that can either reproduce what we already know in more bite-sized pieces or perform rudimentary tasks that we can also do ourselves such as summarisation or sentiment analysis. Even though the model might only ‘know’ things that are also known by humankind, does not mean that everything the model might ‘know’ is also known by any given individual. Therefore, in some way the model is similar to our beloved search engine Google, perhaps more malleable according to the use case at hand and equipped with additional features such as summarization skills.
One example illustrating well how tools like these can be used in education:
2. An auxiliary tasks tool in research: overlapping the previous point, one can augment their knowledge to the knowledge embedded in the data the NLP model has been trained on to some extent. Furthermore, some ideas of use cases include classifying papers by other researchers according to some set of labels and thus building an easily accessible knowledge base. Then, questions can be asked to look up in the text of these papers. Quick one-shot questions can also be asked to models to look up essential general information. However, Google might simply be able to do the same, more reliably. Additionally, converting drafts into nicely written language might be a possibility, but there is quite some logic needed for the successful execution of such a command so this would perhaps entail difficulties for the model. The same would hold for converting written text to more clear language someone outside the field would be able to understand. Quick summarisation of something you have written to send to a research collaborator would also be possible. Writing the abstract or your research paper seems, for now, to be more reliable to write on your own (if your research is outside the boundaries of ‘knowledge’ embedded in the model training data). Still, it can not hurt seeing how an NLP model would summarize your work. Lastly, writing code could help streamline the process of implementing standard algorithms as components of the final project.
3. Data collection for research: especially for political research projects, data collection using social media sentiment analysis for some relevant topic can produce loads of trustworthy data in a matter of moments. In a similar way, it can be used to see how ideas spread on social media, how financial news is processed online and talked about in the public and can finally impact our economy. There might be more possibilities to explore, but the named ones seem to be the most straightforward.
Exemplary Implementation
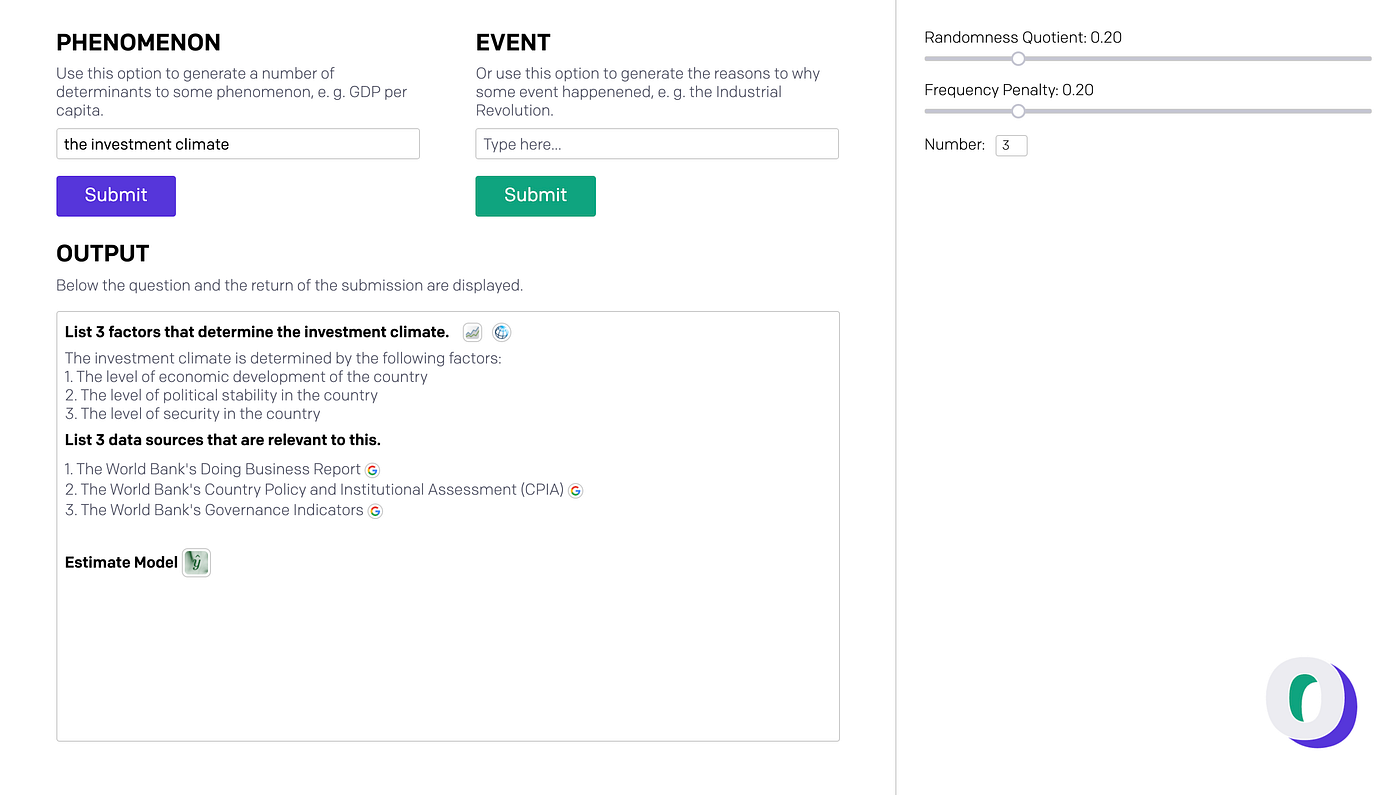
Before writing this article, I also had my go at using an NLP model for the social sciences, to be precise, OpenAI’s GPT-3 for which I was granted beta access. My basic plan was to create an auxiliary and inspirational tool where short questions would be answered with short answers. At its core, I developed two different prompts with which the user can either ask for a number of factors that determine some phenomenon or for an explanation of what caused an event to happen in a limited number of sentences. After some adjusting of the parameters for each different question, generally, the model does its job. For the factor listing prompt, more inaccuracies arise than do for the explanation prompt, possibly because describing events is more of a recalling act than naming factors of some phenomenon, which more often requires building up from the data trained on. In other words, if you can name some special historical event you will also be able to name what caused it. As OpenAI’s GPT-3 was essentially trained on the internet, it was trained on the events registered on the internet and so it also knows the reasons for what caused the most well-documented events as these are often included in the articles that name them. Factors of some certain phenomena are usually less well documented and sometimes will require more extrapolation or interpolation of the data, which has been argued that these NLP models are not that good at.
One example of using the tool:
Conclusion
Natural language processing has come a long way and produced surprising results. Often, on media platforms following certain model publishments, the most stunning examples of what these models are able to do are picked out, such as an interview where carefully designed questions are asked to the model to ensure that it comes up with interesting answers (this article contains explanations why these questions are easy for the model to answer). In reality, when these models are exposed to even moderately complicated questions that require even rudimentary problem-solving, they break down. Nevertheless, NLP models have many uses and with progress in their capabilities continuing, it is quite plausible that natural language processing models will play a sizable part in our near future.





