
Data Cleaning: Inspecting and Wrangling the FIFA 21 Data Using PowerQuery

Background
I organized a #datacleaningchallenge in the data-tech space alongside a fellow Data enthusiast in a bid to create an enabling environment to allow beginners, intermediates, and pro data analysts to flex their data cleaning skills. As the organizer, I was not left behind as I also joined the other participants to transform the dataset provided for the challenge using Microsoft’s PowerQuery editor.

As you already know, data cleaning is one of the core stages every data must go through before analysis. It ensures that the insights generated are accurate and not influenced by any inconsistencies, errors or dirtiness tied to the data.
The specific objectives of the data cleaning process
Before accessing the data for cleaning, I wrote down 2 objectives that should be met after the data cleaning is completed
• Ensure that all the columns have the correct data type
• Numerical columns should be in a format suitable for further calculations and analysis
Meeting these two objectives requires that a good number of factors be checkmated, some of which are; the presence of null entries, empty rows, special characters, irregularities, inconsistent naming conventions etc.
About the dataset
The dataset used for this challenge is the FIFA 21 data. It was sourced from Kaggle and can be accessed here. The dataset was obtained in its raw state after web scrapping from sofifa.com. It contains the details of football players alongside their performance, updated up till 2021. It is worth noting that there are 18979 rows and 77 columns present in the FIFA 21 data.
Data Discovery and Cleaning
The dataset was imported into the Powerquery editor, and loaded for transformation.
The dataset from my observation had numerous issues that were fixed during the cleaning process. Stick with me as I take you through the process of transforming this data from its messy state to a clean state, ready for analysis.
• The 'ID' column has unique numbers assigned to every player
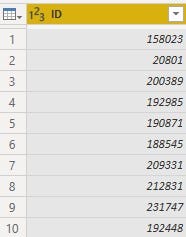
• The 'Name’, 'LongName' and 'PlayerURL' columns all had information relating to players' names. The Name column has names written in the format, 'C. Ronaldo’, the LongName column had the initials, first name, middle name and last name of players in one place while the PlayerURL column had the players' full names embedded within the URL.
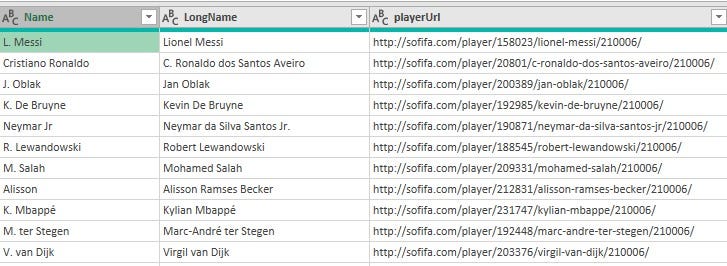
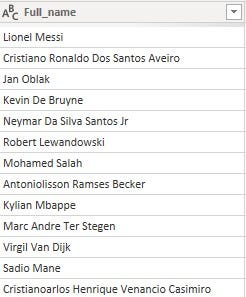
Using the Name column as the only column bearing players' names was not a good idea considering the fact that the first names of the players were shortened to one alphabet. Deciding to settle with the LongName column was not a great idea either since the names in that column contained special characters that would have been more challenging to get rid of. I resorted to extracting the full names of the players from the PlayerURL column.
Process: the column was split using the '/' and '-' delimiters at each occurrence. This process split the column into over 7 columns. The columns bearing the players' names were retained and merged into one column and each letter was capitalized.
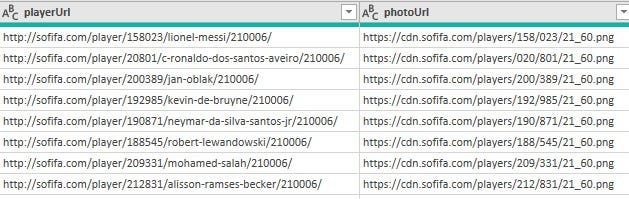
• 'PhotoURL' and 'PlayerURL' columns contained links that can be used to access the image and details of all the players represented in the data. These columns were removed from the data.
• Nationality, Age and Club columns had no missing entries, null values, or data type issues. I considered them okay and moved to the next columns.
• The 'Contract' column had inconsistent values and the wrong data type. The column has 3 categories of values in the format, '23rd July 2020 on loan’, 'Free' and '2018 ~ 2024’.
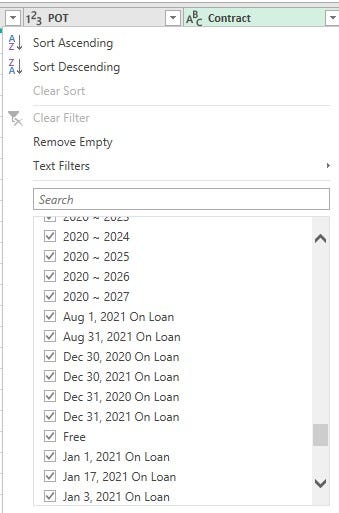
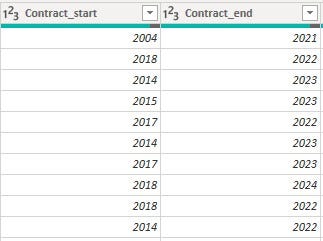
To tackle this issue, I had the column split using the space delimiter to give two columns containing the Contract start date and the Contract end date.
Process: I split the column using 'space' as the delimiter. Over 4 columns were created, got rid of all except the columns with Contract start and Contract end details. The columns were renamed, and the entries which were not in year format were replaced with 'Null’. This was done to allow the conversion of these two new columns to date types and also nullify records of players on 'Loan' and 'Free' from the Contracts column.
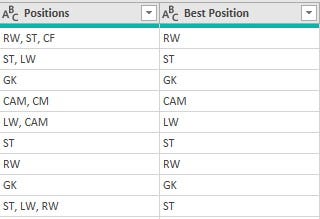
• 'Positions' column was removed because there is another column bearing the 'Best_Position' of each player. The 'Positions' column had the details in the 'Best_Position' column in addition to the extra positions for players that had more than one position.
• 'Joined' column was filtered to see if there are inconsistencies in the data keyed into it. The column has consistent data and the correct data type (date).

• 'Loan_date_end' has 95% empty rows. This is understandable as the total number of players on loan accounts for only 5% of the entire data. Only players on loan have values in this column.

To tackle the problem with the empty spaces, I replaced all empty spaces with 'Null’.
• 'Attacking’, 'Crossing’, 'Finishing’, 'Heading_accuracy’, 'Short_passing’, 'Volleys’, 'Skill’, 'Dribbling’, 'Curve’, 'FK_accuracy’, 'Long_passing’, 'Ball_control’, 'Movement’, 'Acceleration’, 'Spring_speed’, 'Agility’, 'Reactions’, 'Balance’, 'Power’, 'Shot_power’, 'Jumping’, 'Stamina’, 'Strength’, 'Long_shot’, 'Mentality’, 'Aggression’, 'Interception’, 'Positioning’, 'Vision’, 'Penalties’, 'Composure’, 'Defending’, 'Marking’, 'Standing_tackle’, 'Sliding_tackle’, 'Goalkeeping’, 'GK_handling’, 'GK_diving’, 'Gk_kicking’, 'Gk_positioning’, 'Gk_reflexes’, 'Total_stats’, 'Base_stats’, 'Pace’, 'Shooting’, 'Passing’, 'DRI’, 'DEF’, 'Physical’, 'Best_position’, 'Preferred_foot’, 'Attacking_workrate’, and 'Defensive_workrate' were checked and no issues found within the data. The data types were checkmated, and changes were made for some that had wrong data types and column names corrected.
• 'Weak_foot’, 'Skill_moves’, and 'International_reputation' columns all contain ratings on a scale of 1-5. The values in these columns had the special character '☆' in front and the data type was text
I replaced the special character with space, wrote the column names in full and then converted the column data types from text to whole number
• 'Height' and 'Weight' columns had inconsistencies in the units attached to their values. For the 'Height' column, the entries were in the format, '110cm’, 5’2" (feet & inches)
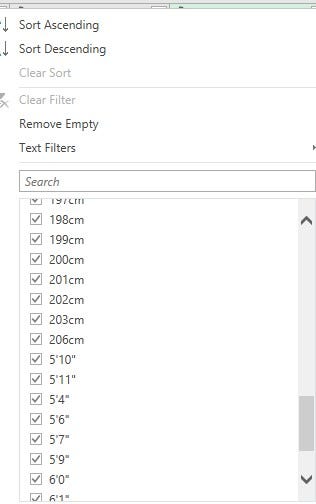
For the 'Weight' column, entries were in the format, '65kg’, '112lbs’
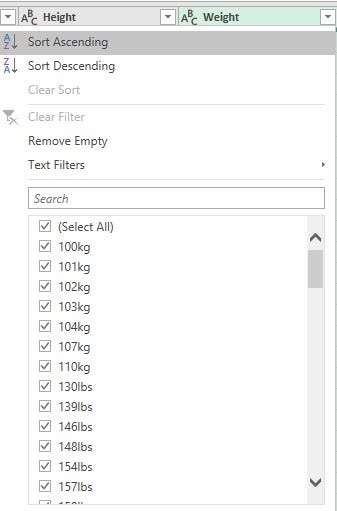
The data type was stored as text. To convert the data type to a whole number, I had to first get rid of the suffixes after each value in both columns. To achieve this goal, the values in the height column in feets&inches were converted to 'cm' and for the weight, the values in lbs were converted to 'kg' before removing the unwanted suffixes
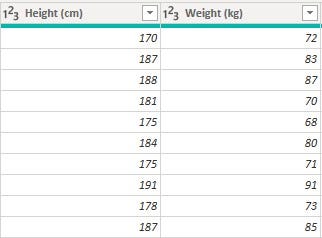
The interconversions were possible using the formula below for height column conversion and weight column conversion
For height: if Text.EndsWith([Height], "cm") then Number.FromText(Text.RemoveSuffix([Height], "cm")) else let feet = Text.BeforeDelimiter([Height], "’"), inches = Text.BeforeDelimiter(Text.AfterDelimiter([Height], "’"), """"), totalInches = (Number.FromText(feet) * 12) + Number.FromText(inches), cm = totalInches * 2.54 in cm
For weight: if Text.EndsWith([Weight], "lbs") then Number.FromText(Text.Start([Weight], Text.Length([Weight]) - 3)) * 0.45359237
else Number.FromText(Text.Start([Weight], Text.Length([Weight]) - 2))
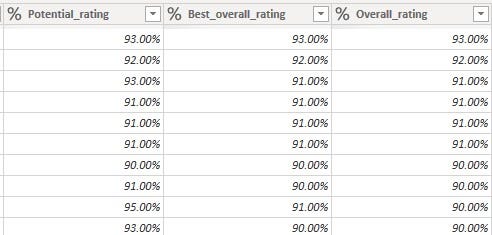
• 'Potential_rating’, 'Best_overall_rating' and 'Overall_rating' columns had values in the range of 1-99
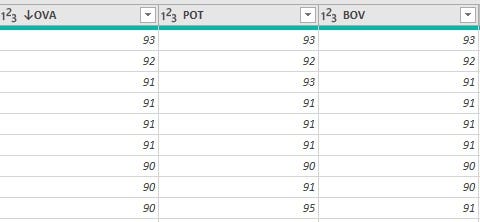
Research about these column names showed that it is best for the values to be represented in percentages. To achieve this, these columns were first converted to integer data types, divided by hundred, and then subsequently converted to the percentage data type which multiplied all the values by a factor of 100
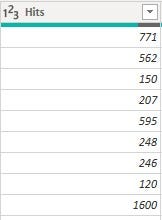
• 'Hits' column was stored as text data type but contained numbers (whole number and decimal number types) with the 'K' suffixes. For context, values like 1600 were stored as 1.6K
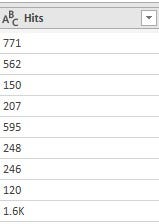
To get these values in numerical format, I created a conditional column which gave an output of 1000 for every row that has 'K' in the 'Hits' column and returned 1 if otherwise. After creating the conditional column, the 'K' in the 'Hits' column was replaced with space and the data type was converted to an integer. The final step involved creating a custom column whose formula was a multiplication of values in the conditional column and that in the Hits column. The custom column was renamed to 'Hits’, and the conditional column and original 'Hits' column were removed
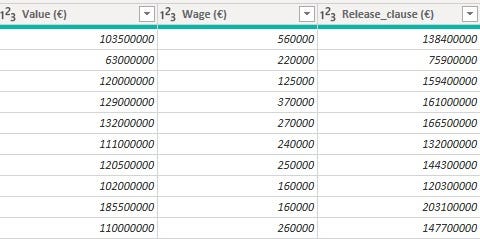
• 'Value’, 'Wage' and 'Release_clause' columns had data type issues and values with suffixes in front. These columns had suffixes 'M' for millions, 'K' for thousands and '€' for euro (currency)
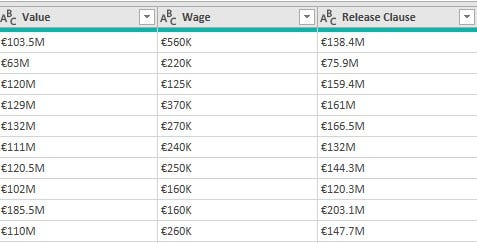
To normalize the values(whole number and decimal) in these columns and get rid of the suffixes, a conditional column was created as in the 'Hits' column. The suffixes were replaced with space, data types were converted, and the custom column was created for the multiplication of values in these original columns and the values in the conditional columns. The new columns containing the normalized values were converted to whole number data types and renamed
Conclusion
Cleaning the FIFA 21 data was a bit challenging. Despite the challenges encountered, the messy dataset was transformed into a state that renders it ready for use in analysis.





